1. 데이터 수집 :
대사물질(Metabolite) 객체들을 특용작물 데이터베이스에서 가져와, 각 대사물질의 이름과 분자 구조(InChI 정보)를 추출합니다.
InChI 정보의 예시는 [그림1]과 같습니다.
 [그림1] InChI 정보 예시
2. 유사도 계산 :
[그림1] InChI 정보 예시
2. 유사도 계산 :
RDKit 라이브러리를 사용하여 각 대사물질의 InChI 정보를 ECFP(Extended Connectivity FingerPrint)로 변환합니다.
분자 지문은 분자의 구조를 나타내는 이진 비트열(0 또는 1로 이루어진 배열)로, 분자의 구조에 대한 특징을 반영합니다.
이 특징들은 화합물 간의 유사도를 계산하는 데 사용됩니다.
이 분자 지문을 활용하여 대사물질 간의 유사도를 계산하고, 결과를 행렬로 저장합니다.
3. 결과 출력 :
계산된 유사도 행렬을 pandas 데이터프레임으로 변환합니다.
유사도 행렬을 콘솔에 출력하고, CSV 파일로 저장하여 나중에 사용할 수 있도록 합니다.
[그림 2]와 같은 csv 파일이 서버 내에 생성됩니다.
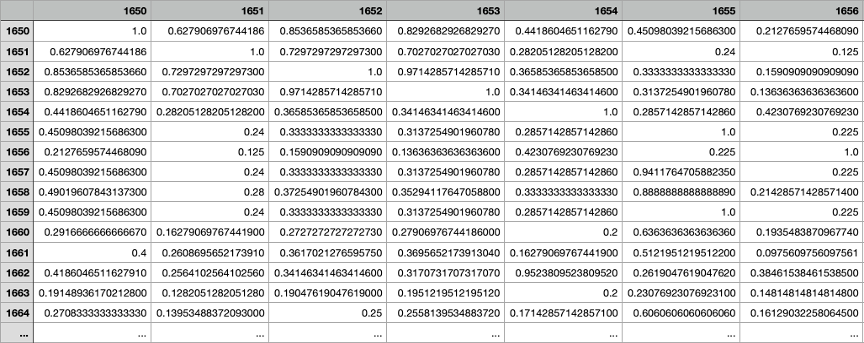 [그림2] 대사물질 간 유사도를 숫자로 나타낸 csv 파일. 1에 가까울수록 유사도가 높다.
[그림2] 대사물질 간 유사도를 숫자로 나타낸 csv 파일. 1에 가까울수록 유사도가 높다.
가로, 세로의 숫자는 대사물질의 고유 키입니다.
이 csv 파일을 바탕으로 본 대사물질과 유사한 대사물질을 찾습니다.
